A combination of powerful technologies ensures NetGuardians’ NG|Screener data analytics risk platform can detect and prevent fraud in real time at the volumes required by financial institutions. Jerome Kehrli explains
Catching fraudsters in the act of stealing money from bank accounts is a split-second business. A one-second delay and the money has gone. Real-time monitoring, analytics and blocking are essential.
But this puts huge demands on the analytics systems that must quickly crunch enormous amounts of data – both historic and new feeds – to decide in less than a second whether an action is suspicious. To make matters harder, these systems need to have low latency, high throughput and be highly scalable and resilient.NetGuardians has developed its flagship behavioral and fraud-prevention solution NG|Screener to do all this. Designed specifically for financial institutions, it’s a Big Data analytics risk platform that can prevent fraud on a large scale. It analyzes user behavior and transactions in real time by managing and operating Big Data technologies and Augmented Intelligence to detect fraud and block suspicious activity.
Technology is an enabler
Essentially, Lambda architecture is the key to allowing NetGuardians to enter the real-time transaction monitoring business. And the Lambda architecture is supported by NG|Screener’s Big Data components – Apache Kafka, Apache Mesos, Apache Spark and ElasticSearch.
ElasticSearch delivers real-time updating (fast indexing) with astonishing search/read response times, while Apache Kafka addresses event-at-a-time processing with millisecond latency as well as stateful (memory) processing including distributed joins and aggregations. Apache Spark is then used to process hundreds of thousands of records per node per second and offers near-linear scalability. Meanwhile, Mesos provides applications with APIs for resource management and scheduling across the entire data center and including any cloud environment
With its micro batch approach, batches can be as small as a few milliseconds. This allows sub-second latency while simultaneously ensuring very high throughput and access to Spark’s power and versatility to implement high-level analytics use cases.
A Lambda architecture reunites our real-time and batch analytics. This is designed to handle massive quantities of data by taking advantage of both batch and stream processing. This means we can balance latency, throughput and fault-tolerance needs with real-time stream processing to see the data.
Lambda architecture overview
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. This approach is designed to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch
data, while simultaneously using real-time stream processing to provide views of online data.
Lambda architecture is designed to handle both real-time and historically aggregated batched data in an integrated fashion. It separates the duties of real-time and batch processing so purpose-built engines, processes, and storage can be used for each. Serving and query layers present a unified view of all the data.
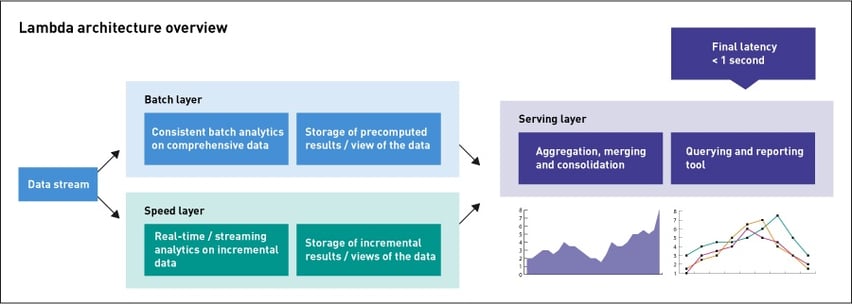
As new data are introduced to the system, they are processed simultaneously by both the batch layer and the speed layer. The batch layer is an append-only repository containing unprocessed raw data. It periodically or continuously runs jobs that create views of the batch data – aggregations or representations of the most up-to-date versions. These batch views are sent to the serving layer, where they are available for analytic queries.
As those data are appended to the batch layer, they are also simultaneously streamed into the speed layer. The speed layer is designed to allow queries to reflect the most up-to-date information – necessary because the serving layer’s views can only be created by relatively long-running batch jobs. The speed layer computes only the data needed to bring the serving layer’s views to real time – for instance, calculating totals for the past few minutes that are missing in the serving layer’s view.
By merging data from the speed and serving layers, low latency queries can include data that are based on computationally expensive batch processing, as well as real-time data.
Another important feature is that the raw source data are always available, so redefinition and recomputation of the batch and speed views can be performed on demand. The batch layer provides a Big Data repository for machine learning and advanced analytics, while the speed and serving layers provide a platform for real-time analytics.
A breakthrough in fraud analytics
At NetGuardians, some of our analytics use cases have to consider extended contextual information, for example about transaction activities, to build user and customer profiles or analyze their past behaviors. Building such contextual information typically requires analyzing over and over again billions of business events and peta-bytes of data.
Rebuilding these profiles or recreating the aggregated statistical metrics would require many minutes using a typical batch-processing approach. By taking an incremental building approach and using the Lambda architecture, NG|Screener can rebuild the historical part while the latest data are considered by the speed layer to provide an up-to-date (as far as real-time) view of the reality. The serving layer consolidates both results to provide always up-to-date and accurate views of these profiles or other aggregated statistical metrics.
The same technologies and approaches deployed in the speed layer to provide up-to-date views of the reality are used to score and classify business events, such as financial transactions in real-time. This means we don’t need strong real-time with millisecond-order latency and producing a risk score in under a second is sufficient.
For systems that do regularly have to compute burst of events made up of several hundreds of entries per second, we have incorporated Apache Spark streaming.
Summary
NG|Screener’s unique combination of technologies within a state-of-the-art Lambda architecture delivers:
- Up-to-date and second-close view of the reality in contextual information, user / customer profiles and other key periodic statistical metrics
- Classification and scoring of business events real-time at a very high throughput
- Ability to score very large data sets
- Simplicity and easy maintenance since we can share significant sections of codes between the batch layer and the speed layer because both are built on Apache Spark
- Resolution of operational complexity of big computation on historical data by dividing the work incrementally


