Every transaction leaves a digital trace. When your fraud prevention software knows what to look for within that trace, it can distinguish between an account takeover and an authorized push payment fraud, giving vital context to better protect customers from the fraudsters, writes Vivien Bonvin.
It’s sadly still all too common for bank customers to become victims of fraudsters. In the first article of our series on identifying different fraud types, we explained how knowing the type of fraud being attempted helps stop more fraudulent transactions. Here, we explain how our software monitors and models the technical aspects of a transaction so that it can correctly distinguish between an authorized push payment (APP) fraud from an account takeover, for example.
Frauds leave a trace
When a banking transaction is processed, it leaves a unique trace: the time it was input, when it was timed to be executed, the exact user journey through an e-banking application and much more. Each transaction is different, so each trace is unique and can tell us important information – but only if we know where to look. Consider these two very different but typical fraud types – account takeover and authorized push-payment fraud (APP).
In a typical account takeover, a malware (a RETEFE worm or similar) is activated on the target’s computer. The malware steals e-banking credentials, allowing the fraudster access to the victim’s e-banking account. As the fraudulent transaction is automated (they are rarely completed by a person), the fraudster’s system takes only milliseconds to log in, input and validate the transaction and then log out. The trace left behind is very thin.
"Each transaction is different, so each trace is unique and can tell us important information – but only if we know where to look."
With authorized push-payment frauds, a customer might find a great deal on a popular online marketplace offering discounted luxury goods in a flash sale. She logs into her e-banking, looks at her account balance and checks her recent and outstanding payments. She spends a few minutes thinking about whether the offer is too good to be true, concludes that the marketplace is reputable and proceeds to authorize payment. Unfortunately, it is indeed too good to be true: the purchase never arrives. This time, the trace is long; she visited many pages of the e-banking app and took her time between login and logout.
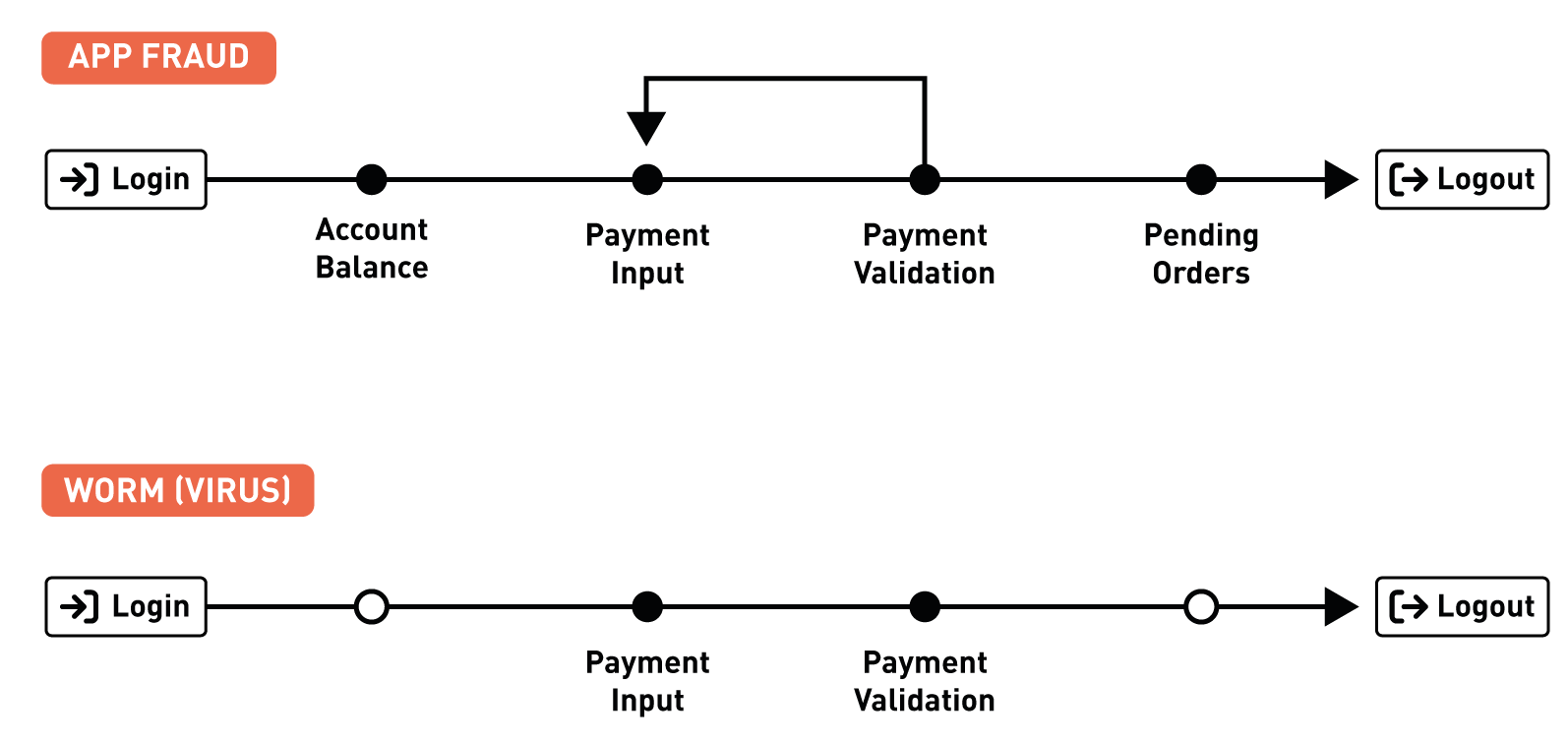
A worm does not need to know about your account balance or pending orders.
Frauds have a type
Like most fraud fighters, at NetGuardians we work hand-in-hand with our banking partners to get to the bottom of each fraud case. We use the FraudClassifier Model, a classification standard defined by the US Federal Reserve, to build context, identify types of fraud and develop a business understanding of different fraud cases.
This very human approach to classifying fraud types on its own uses only a fraction – if any – of the digital traces left by frauds across banking systems. Essentially, it is an analogue procedure as it uses only information that a human investigator can understand to determine a fraud type, such as amount, destination country, currency, beneficiary identity, etc. But there’s so much more information in the “trace space” that can offer clues as to whether the transaction is genuine.
As demonstrated by the examples of account takeover and APP fraud outlined above, these digital traces include, for example, how fast a user typed in their login, or which pages of the e-banking app they visited before approving the payment. At NetGuardians, we realized that by incorporating these trace space features into our screening, we could learn about fraud types, thereby enhancing our ability to prevent them.
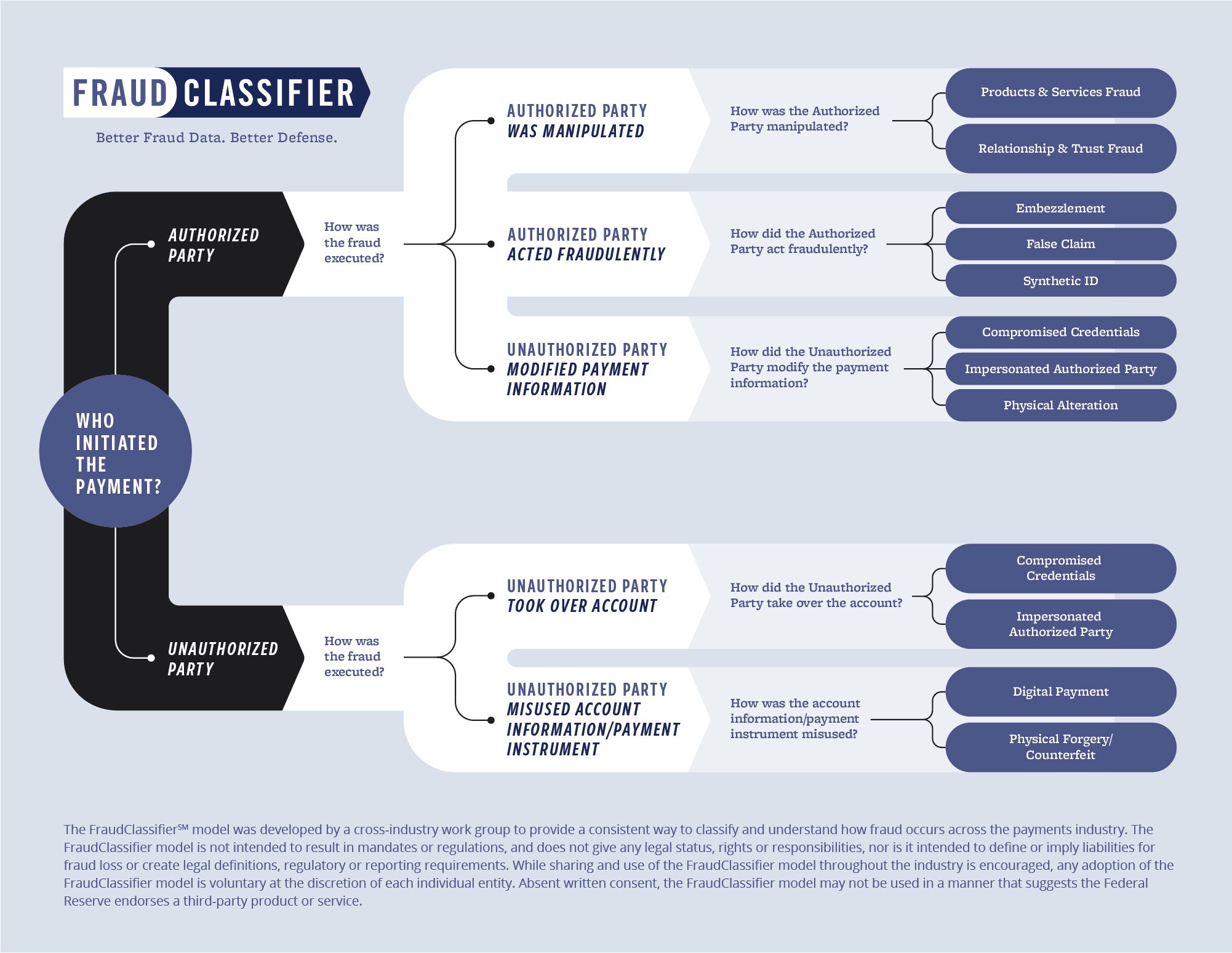
Image source: https://fedpaymentsimprovement.org/strategic-initiatives/payments-security/fraudclassifier-model/
"We need a solution that could accurately interpret and map the risks"
Joining traces and types
As well as using the standard Fraud Classifier Model in our work, at NetGuardians we have developed our own 3D AI technology to fight banking fraud. This proprietary technology creates and assesses trace data features for all transactions flowing through our solution – the trace space. It models correlations between the created features and the binary label (fraud/non-fraud) of past transactions. This, combined with the business understanding explained above, gives us access to a new range of labels we can model that ultimately allows us to identify the type of fraudulent transaction.
When developing this technology, we decided not to build a multi-label classification model similar to a boosting model or neural network. This is because we know from experience that these kinds of complex models are at risk of under-performing if they are not carefully adapted to the underlying data. As frauds are extremely under-represented when compared against the volume of genuine transactions, we realized that we needed a solution that could accurately interpret and map the risks associated with various technical data that was in short supply with the different fraud types.
That is exactly what we have built. When banks use this information in interactions with their customers, it makes our fraud-prevention software even more efficient, helping to protect their customers and their reputations.
If you would like to know more about the tools we used to model the trace space and how we developed it, stay tuned, for the third article on our Know Your Fraud series here.


