Powerful modeling and mapping technology allows our cutting-edge fraud-identification software to help banks, their customers and regulators understand a fraudulent transaction in an explainable way, writes Vivien Bonvin.
Many frauds are detected by banks, but the customer sometimes overrides an alert to complete the transaction despite a fraud warning. In the first article in this series, we showed that when the fraud-detection system nails down exactly what kind of fraud is being attempted, distinguishing between an authorized push payment fraud from an account takeover fraud, the bank is armed with detailed information as to why the customer should stop the payment.
In the second article, we explained how NetGuardians can distinguish between fraud types by drilling down into the “trace space” – the data found in the traces left between and including logging on and logging off for every transaction. In this article, we focus on the sophisticated digital tools we use to process this trace space.
Two powerful technical tools
In the high-dimensional trace space, we knew that we needed to cluster frauds by type in the right way. We quickly found that more traditional clustering techniques, such as K-means or Gaussian Mixture Models, gave mixed results. The mapping we tried to build between the data features from the trace space and fraud type was simply too complex to be easily captured.
Instead, we turned to two open-source tools from Canada’s Tutte Institute. The first is UMAP, a manifold learning tool that allows us to perform dimensionality reduction while preserving large-scale structures from high-dimensional space. The second is HDBSCAN, a clustering algorithm that makes no prior assumptions on the shape or density of clusters. Combined, they offered a more robust approach to clustering fraud types.
Dimensionality reduction
To make things visual, let’s imagine our original trace space is three-dimensional, and as a result we can only engineer three different features from the traces left by transactions. With these trace features, we ask UMAP to find a two-dimensional surface (imagine a folded piece of paper within this three-dimensional space), placing all the three-dimensional points as close as possible to this surface. Once this almost optimal surface has been found, we can mark the position of the three-dimensional transactions on the surface and unfold it to visualize it in two dimensions.
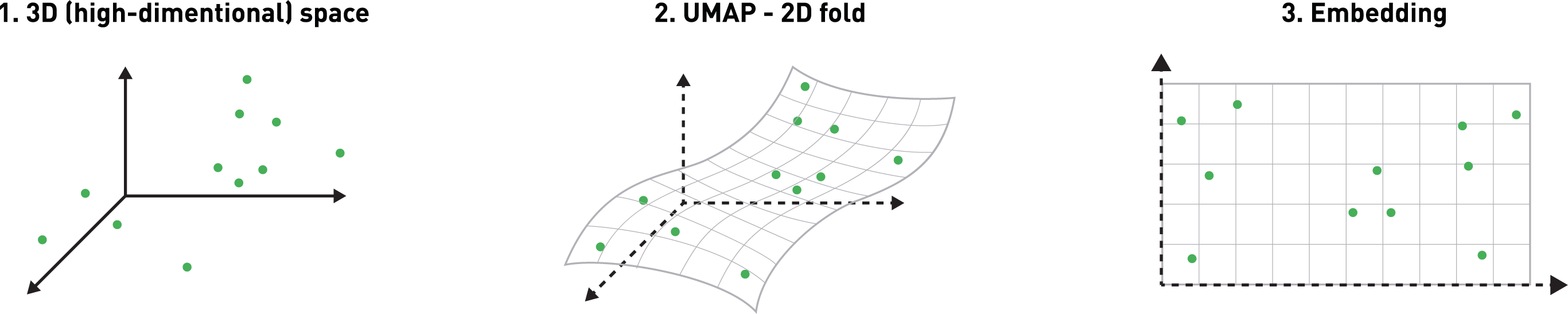
In practice, we compute dozens of trace-space features for our transactions. In such a high-dimensional space, we cannot possibly build a good visual representation of where our transactions are located. So, we trained UMAP to build a two-dimensional embedding of the high-dimensional data. By finding a two-dimensional fold on which fraudulent transactions of the same type are closer to each other, it can simultaneously reduce the dimensionality of the trace space while keeping the overall high-dimensional arrangement of points intact and group transactions of the same type together.
Although higher-dimensional embedding might suit our needs better, we chose a two-dimensional space as we know banks and regulators would rather trust a marginally less efficient process that they can understand visually than a black box model.
"Our modeling does not replace human investigation, but rather guide it. It offers additional intelligence to the analyst at the start of the investigation."
Clusterig and label inference
Once this embedding is done, we are left with trying to group transactions in a meaningful way.
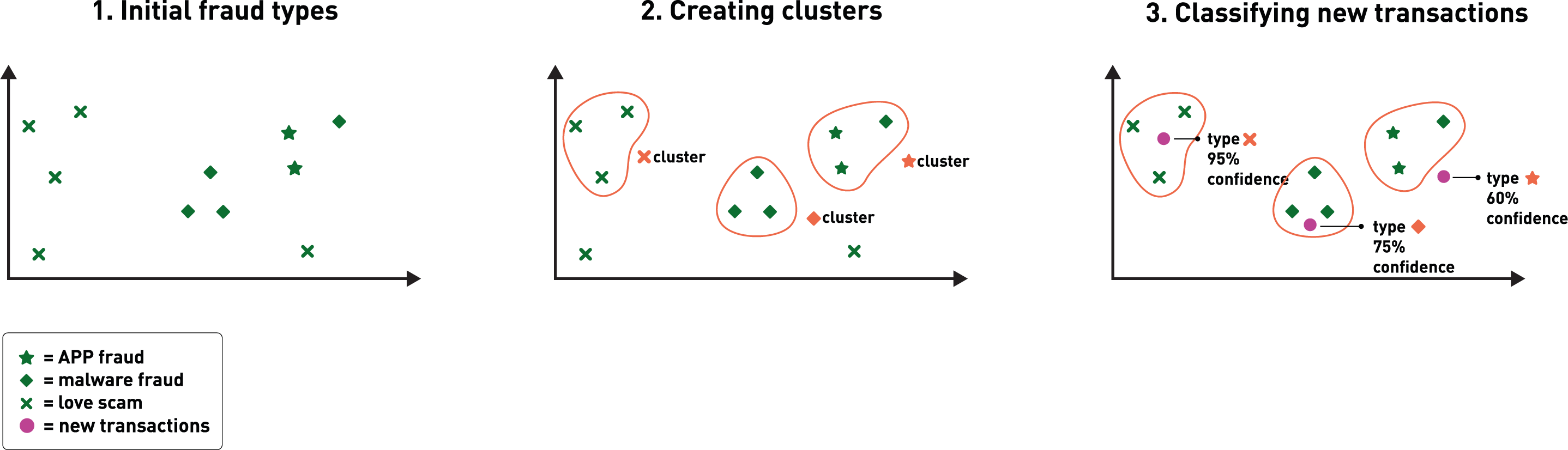
HDBSCAN is one of the best algorithms to do this as it can cluster points together without prior assumptions about the size or shape of clusters. This is important because the structures formed by the embedded transactions can be wild shapes that would not be recognized as clusters by more traditional algorithms.
Once HDBSCAN identifies these clusters, we can assign them a dominant fraud type according to the balance of fraud types of the individual frauds composing the cluster. Each time we categorize a new fraudulent transaction, we embed it in our two-dimensional space using the previously learned UMAP dimensionality reduction and associate it to one of the clusters. Using the clusters’ dominant fraud type assigned during training, we can then predict the fraud type for a new transaction.
Results
This new intelligence about the frauds is a great asset for analysts. It correctly identifies the majority of the fraud types with no additional impact on the daily business of banks and even reduces the time it takes them to investigate suspicious cases. It can also help create a richer context to use when contacting customers – as we know, accurate context can make all the difference when it comes to convincing a customer not to execute a scam.
"We have a comprehensive and efficient solution that does not sacrifice understandability for performance."
Moving forward
This cutting-edge work bridges a gap between two worlds – the business understanding of a human being and the automatic feature generation provided by AI. The fraud type classification we perform is primarily a human process. By building a model of that process using machine-learning techniques, we model the human understanding and classification of fraud types, drawing on a more diverse set of features from the trace space than a human investigator could possibly evaluate in the available time.
This is crucial as it means our modeling won’t replace human investigation, but rather guide it. It offers additional intelligence to the analyst at the start of the investigation.
As data scientists, we see two ways to strengthen our current approach. First, we can increase the overall accuracy of predicted fraud types by developing advanced feature-generation techniques. This will allow us to further fine-tune our dimensionality reduction and clustering algorithms and optimize every step of the process to the trace data at hand. Second, we can further refine the classification of fraud types by gathering more data to model.
Both paths benefit from more intelligence. By building a community of banks around NetGuardians’ trusted approach, we can leverage data not simply at the level of an individual bank, but at a consortium level. This is the heart of our Community Scoring and Intelligence solution.
The more community intelligence we have, the more fraud cases we have to learn from, which results in better fraud-fighting models. Ultimately, we will have a comprehensive and efficient solution that does not sacrifice understandability for performance. It’s another example that proves when we fight fraud together, everyone is a winner.

